
Image Refinement with Cross Attention Control
If you’ve been keeping up with the latest Stable Diffusion forks, you may have seen prompt editing get merged to the master branch of the Automatic111 repo a few days ago. There’s not a lot of information on how to use this other than a comment in the commit.
I believe the repo this originated from is Cross Attention Control. The README here describes more uses than the AUTOMATIC111 commit comment talks about. I wanted to do some testing on prompt editing anyway and thought I’d see what else out of the Cross Attention Control repo (if anything) worked and how well it performed.
This was one of the most impressive features I’ve tested so far – Here’s a quick peek swapping out prompts. All images are using the same seed:
 |  |  |
|---|---|---|
A whale surfacing | a [whale:starfish:0.1] surfacing | a starfish surfacing |
A big limitation of the AI image generators is lack of fine tuning controls. I often get some image that’s close to what I had in my mind, but rather than furiously fighting with prompts for hours, like the poor author of this post, I’ve been waiting to be able to take an image that’s almost what I want and modify within the model it to be closer to my vision.
I think this delivers on that pretty well and has been a lot more impressive than my testing with textual inversion, which has been fairly lackluster but promises similar workflow improvements (by re/teaching the model a concept)
I suspect this is mostly due to poor embeddings – I need to do some more testing on that soon, but I’m starting to think textual embeddings are going to be useful only for representing objects that are too rare or unique to be in the AI model. For most known things/styles, this seems like a more effective approach to fine tuning.
And kudos to the maintainers of the AUTOMATIC111 repo – Even while writing this there have been 10+ new features added including outpainting which I’ve been eagerly waiting for!
Cross Attention Control Functions
The Github repo describes and gives examples of the following uses:
Target replacement to swap out an object in an image
Style injection to keep the same base image but modify the tone/artist/etc
Global editing which is not entirely clear to me and I think is just globally applied concepts that aren’t styles, like weather effects or seasons
Direct token attention control to boost or deboost tokens/terms in a prompt
There also looks to be a way to merge images of 2 different prompts together described here.
I was not able to find a way to do this in the AUTOMATIC111 repo. There is a way to merge images of the same prompt, which we will look at below, but I don’t believe this is part of the Cross Attention Control merge.
From my limited understanding, all of these essentially work generally in the same way. As the image is generated, the prompt is switched out, on the fly, based on your inputs. This could replace a subject or adjective in an image or add additional words to a prompt midway through generation.
Now let’s run some tests.

All test variations will be run from from the same seed and other generation settings. I’ll give some extra information on how I ran the tests in case you want to run your own.
Bomber Object Replacement Test
To start, let’s make a vintage bomber aerial photograph. We can just run some batches of images with random seeds until we get something we like.
After a few generations, we get this:
 |
|---|
bomber in flight, wide shot |
Now, what if we want the same image but the bomber should be pink? If we just run the same settings and seed and change the prompt, the results are not consistent with our original image:
 |
|---|
pink bomber in flight, wide shot |
Using Cross Attention Control, we can tell the generation to start with the original prompt we used and switch it at some % through the generation. Here, we’re using 100 steps, so the following prompt will switch to ‘pink bomber in flight’ at 50 steps (50%):
 |
|---|
[bomber:pink bomber:0.5] in flight, wide shot |
Not exactly what we were looking for, but much closer to our original image and intention. What if we don’t even want a bomber at all. Let’s replace the entire bomber with Paul Rudd:
 |
|---|
[bomber:paul rudd:0.3] in flight, wide shot |
Awesome. Here are some other style or object replacement tests based on this image. Note, you can add words in addition to replace words, which you’ll see in the prompts below:
 |  |  |  |
|---|---|---|---|
[bomber:f16:0.28] in flight, wide shot | [vaporwave:.15] bomber in flight, wide shot | [steampunk:.25] bomber in flight, wide shot | [octane render:.15] bomber in flight, wide shot |
Colorful Moon - Token Attention Control Color Test
I did not see Token Attention Control called out in the commit comment explaining how to use this new merge, but it does work. This seems like it may even be a part of some other fork that was merged previously.
In any case, we can take an image and fine tune it by adding + or - to different tokens. Multiple +s and -s can be used for greater effect. This test is pretty simple, but we’ll use this again in the next test with more interesting results.
 |
|---|
a red and blue moon |
 |  |
|---|---|
a -red and blue moon | a red and +blue moon |
Token control looks pretty hit or miss depending on the token and image. It seems to generally work, but when we ask for more red and less blue below, we get the bluest image of the whole set.
Since we know SD knows what ‘red’ and ‘blue’ are, I assume it does not really understand where the colors are in the image. This isn’t analyzing the image like a Photoshop image filter would by looking at the pixels and I realize don’t really understand what it’s doing or how to explain it failing like this.
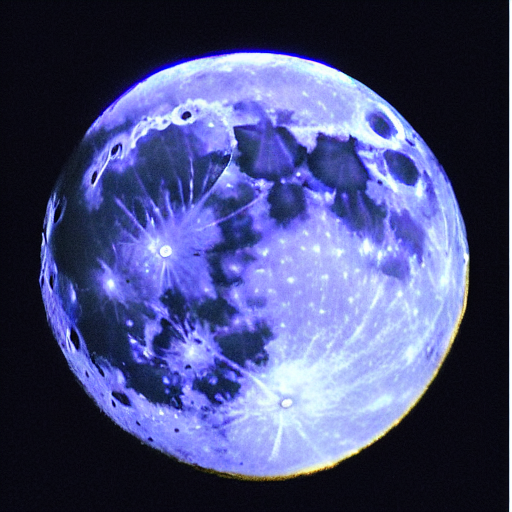 |
|---|
a +red and -blue moon |
Fruit on the Beach - Putting it all together
Let’s see what we can make with one of my favorite AI Image prompts a giant glittery cantaloupe on the beach at sunset.
Before SD released, most free AI image services couldn’t deliver very well on this prompt, so I kept using it. Let’s use what we learned so far to try to tweak the scene to our liking, swap out the cantaloupe for other fruits, and have some famous artists complete the image.
Here’s our starting image:
 |
|---|
giant glittery cantaloupe on the beach at sunset |
SD does a good job on the initial prompt but that’s not glittery enough for what I’m thinking.
 |
|---|
giant ++++glittery cantaloupe on the beach at sunset |
We can do a couple of tests to subjectively boost/decrease the other tokens to tweak even more.
 |  |
|---|---|
giant +++glittery ++++cantaloupe on the beach at ---sunset | ---giant +glittery ++cantaloupe on the +beach at ---sunset |
Awesome. Cantaloupes aren’t very popular or recognizable – Let’s try taking the image above, on the right, and using some more common fruits. Note how using different values for when the prompt will change affects the output.
 |  |
|---|---|
---giant +glittery [++cantaloupe:++apple:.5] on the +beach at ---sunset | ---giant +glittery [++cantaloupe:++apple:.2] on the +beach at ---sunset |
 |  |
|---|---|
---giant +glittery [++cantaloupe:++banana:.02] on the +beach at ---sunset | ---giant +glittery [++cantaloupe:++banana:.01] on the +beach at ---sunset |
For comparison, here are the apple and banana images without prompt switching and using the same seed/settings. They are similar and true to the prompt, but lose a lot from our original image.
 |  |
|---|---|
---giant +glittery ++apple on the +beach at ---sunset | ---giant +glittery ++banana on the +beach at ---sunset |
Dali Take the Wheel
We have the pretty good looking glittery apple picture based on our cantaloupe picture above – Now let’s see what Stable Diffusion thinks Salvador Dali would do if we gave him that picture midway through generation.
Note, if we don’t match the prompt switches, he’ll draw us both fruits!
 |  |
|---|---|
[salvador dali painting of:.2] ---giant +glittery [++cantaloupe:++apple:.2] on the +beach at ---sunset | [salvador dali painting of:.05] ---giant +glittery [++cantaloupe:++apple:.2] on the +beach at ---sunset |
Those are slightly interesting, but let’s just give him it from the beginning.
Note, while doing these tests, I randomly tried [term:.00] which should technically be the same as term as it would get added to the prompt at step 0. This does create different images, as you can see below.
Perhaps terms in quotes can’t be added to the first step and this is the same as [term: .01] at 100 steps, but I have not confirmed that.
 |  |
|---|---|
salvador dali painting of ---giant +glittery [++cantaloupe:++apple:.2] on the +beach at ---sunset | [salvador dali painting of:.00] ---giant +glittery [++cantaloupe:++apple:.2] on the +beach at ---sunset |
OK, that looks like a great stopping point. Let’s do some outpainting in DALL-E and use this for the hero image for this post!
 |
|---|
Merging Seeds Tests
As I said, while I couldn’t find the tool to merge images of different prompts described here, I did find (I assume from a different merged fork) a way to combine different seeds from the same prompt.
For the Automatic111 repo, this is found by clicking the Extra button next to the seed input in txt2img
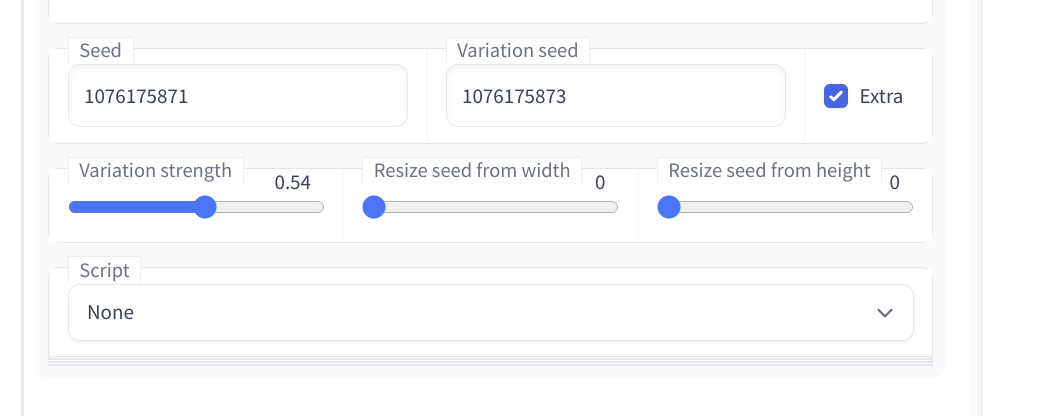
To run a test like below, enter a prompt and set a batch size your GPU can handle. Run generations until you find a good base image and modifier image you like. Enter the seeds in the UI and you’re ready to go.
Note, the info output for batch generations appears to be broken and only shows the initial seed, meaning you’ll need to add the image’s position - 1 to the seed to get the correct value. The seed for the image below is 4101654952 = 4101654947 + 5.
Alien Landscapes
Running the prompt an alien landscape with giant blue and orange tropical trees with random seeds, we eventually get these 2 images. Let’s try to merge them to get the look and style of right image with the layout of the left image.
 |  |
|---|
After some failures and settings tweaking, this eventually seemed to work to some degree, though I don’t really see the ‘style’ of trees in the right image in the ‘successful’ generation.
 |  |  |
|---|
 |
|---|
Bangkok
Let’s try a similar test with some AI generated photos. These 2 photos of Bangkok were generated with the same prompt. Can we ‘merge’ them to get a photo that looks like the left image but has the gold structure in the right image?
 |  |
|---|
 |
|---|
Not bad. We changed perspective some but I definitely think both images subjects and ‘feel’ are represented in both images.
I tried playing with the scale sliders for the variation to try to shrink the gold structure, hoping it would be somewhere else in the background. This kind of worked. It looks like it shrunk the structure, but not as I intended. It wants to put it on top of a skyscraper regardless of settings.
 |  |
|---|
Final Thoughts
For a few quick tests, I think these results are very impressive. I’m sure with a bit more time, effort, and refinement you could get extremely close to the image or modifications you’re looking for. Share your tips below in the comments.
Next time we will hopefully look at textual embeddings and outpainting in Stable Diffusion, which released yesterday.